흑백요리사2 ‘요리괴물’은 정말 우매함의 봉우리일까? (더닝-크루거)
우리가 틀린 더닝-크루거에 속는 이유
흑백요리사 시즌2에 요리괴물이 출연합니다.

넷플릭스 <흑백요리사: 요리 계급 전쟁> 시즌 2를 보다 보면, 시청자들이 심리학 용어를 가장 먼저 소환하는 순간이 있습니다. 57년 경력의 중식 대가 후덕죽 셰프와, 스스로를 천재라 부르며 강한 확신을 내세운 ‘요리 괴물’이 맞붙는 구도입니다. 요리 괴물의 태도를 본 사람들은 즉각적으로 “저게 바로 더닝-크루거 효과다”라는 진단을 내립니다.
요리괴물 (흑수저): 세계적인 미쉐린 스타 레스토랑들을 거치며 자신을 '천재'라 서슴없이 지칭하는, 강한 자기 확신으로 무장한 젊은 도전자입니다.

후덕죽 셰프 (백수저): 한국 중식의 전설, 신라호텔 '팔선'을 40년간 이끌며 국내 최초로 '불도장'을 선보인 57년 경력의 대가입니다.
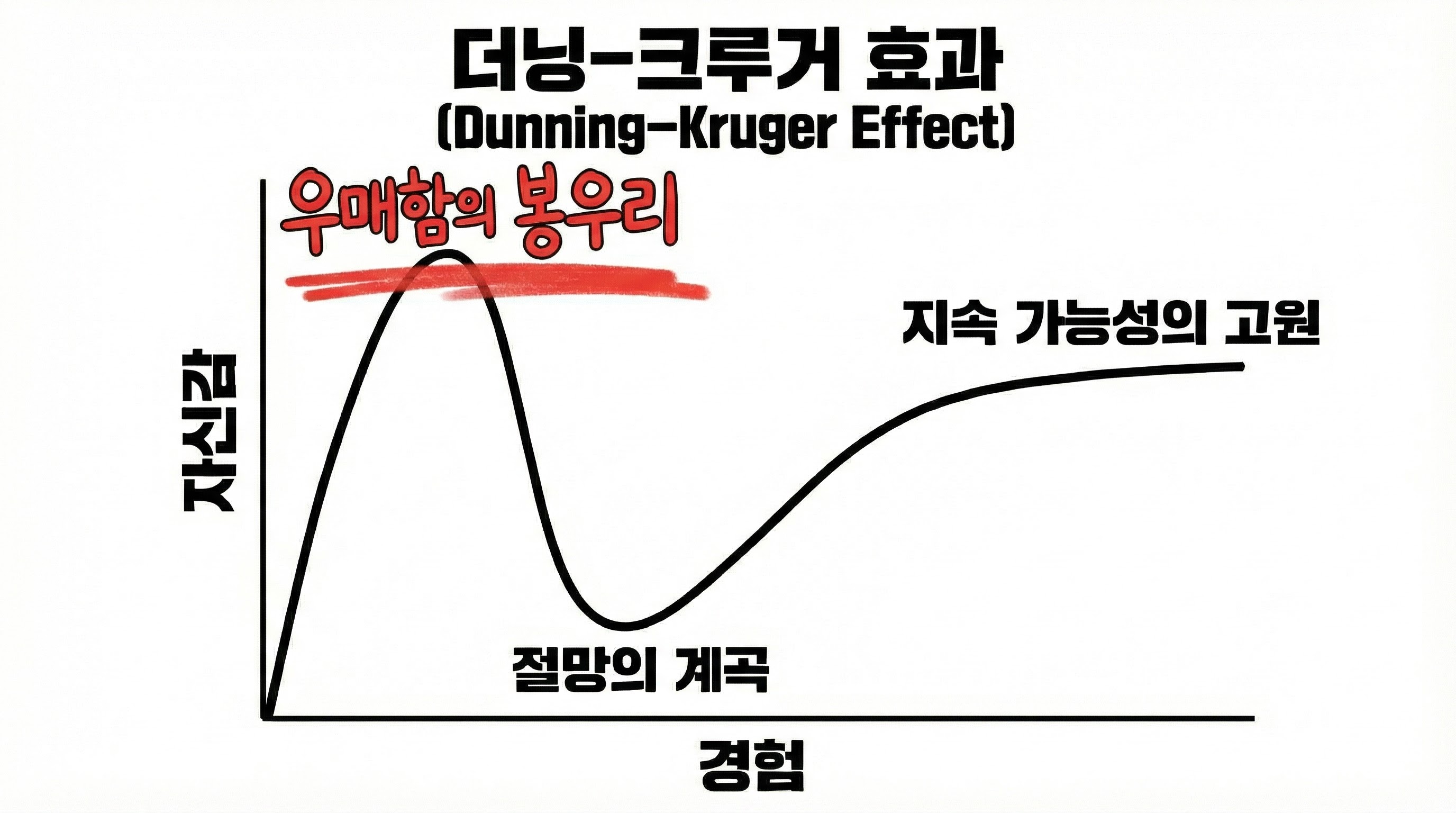
사실 우리는 이런 대비에 유독 민감합니다. 이제 막 성취를 맛본 이의 넘치는 자신감과 오랜 세월을 견딘 대가의 정중함이 충돌할 때, 머릿속에는 익숙한 곡선 하나가 그려지기 때문입니다. 지식이 얕을 때 자신감이 치솟는 ‘우매함의 봉우리’에 섰다가, 현실을 마주하고 ‘절망의 계곡’으로 추락한다는 그 유명한 그래프 말입니다.
그런데 여기서 질문이 시작됩니다.
우리가 떠올리는 그 그래프는 정말 ‘더닝-크루거 효과’를 그대로 그린 것일까요? 만약 그것이 실제와 다른 그림이라면, 왜 우리는 그 틀린 그림에 이토록 쉽게 설득되는 것일까요?
나아가 AI 비즈니스와 기술의 본질을 탐구하는 USLAB AI가 왜 지금 이 시점에 요리 대결과 심리학 용어를 꺼내 들었는지에 대한 질문이기도 합니다. 생성형 AI는 우리를 그 어느 때보다 빠르고 높게, 그리고 정교하게 설계된 ‘우매함의 봉우리’로 밀어 올리는 강력한 도구이기 때문입니다.
1장. 현우진 강사가 말한 더닝-크루거: 성장하면 겸손해지는 이유
현우진 강사가 더닝-크루거 효과를 이야기하며 들려준 경험담은, 이 현상을 가장 인간적으로 보여줍니다. 초창기에는 “내가 꽤 잘한다”는 확신이 컸는데, 시간이 지나 예전 강의를 다시 보니 오히려 부족한 점이 선명하게 보였다는 이야기입니다. 그 순간, ‘내가 착각했구나’가 아니라 ‘이제야 보이기 시작했구나’가 됩니다.
이게 더닝-크루거의 핵심과 맞닿아 있습니다. 더닝-크루거는 남을 평가하기 위한 낙인이 아니라, “사람은 왜 자기 실력을 정확히 보기 어려운가”에 대한 경고입니다. 더닝 본인도 이 효과를 “그들”이 아니라 “우리”에 대한 이야기라고 강조합니다.
성장할수록 겸손해지는 이유도 여기에 있습니다. 겸손해서 성장하는 경우도 있지만, 더 자주 일어나는 방향은 반대입니다. 성장하니까—기준선이 생기니까—예전의 허점이 눈에 들어오고, 그때부터 말이 줄어듭니다.
2장. 반전: ‘우매함의 봉우리’ 그래프는 원논문에 없습니다
여기서 반전이 나옵니다.
인터넷에서 가장 유명한 ‘봉우리-계곡-비탈-고원’ 곡선은 더닝과 크루거의 1999년 원논문에 실린 그래프가 아닙니다. 심리학자들이 데이터를 그렇게 그려서 “여기 봉우리!”라고 표시한 적이 없습니다.
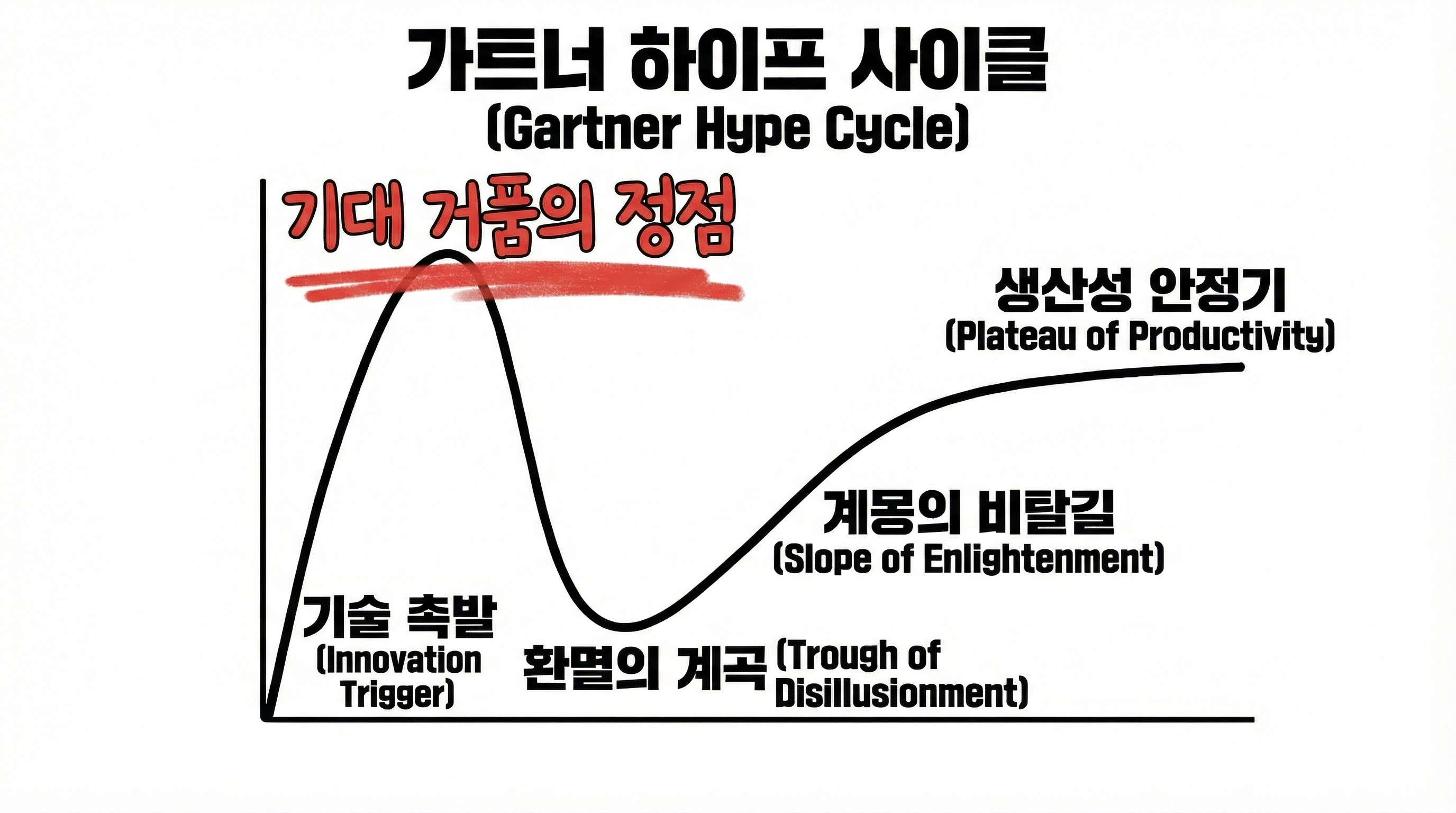
오히려 그 형태는, 신기술이 등장한 뒤 기대가 과열됐다가 꺼지고, 시간이 지나 현실에 안착하는 과정을 설명하는 ‘가트너 하이프 사이클’과 놀랄 만큼 닮아 있습니다. 그래서 ‘더닝-크루거 곡선’으로 퍼진 그림들 중 상당수는, 모양을 빌려오고 라벨만 바꿔 붙인 경우가 많습니다.
그럼에도 그 그래프가 강력한 이유는 분명합니다. 한 번에 이야기가 되기 때문입니다. ‘오만→현타→각성→성장’이라는 서사가 눈앞에 그려지면, 사람은 데이터보다 서사에 먼저 끌립니다. 그래서 “틀렸는데 더 잘 속이는” 그래프가 됩니다.
3장. 진짜 더닝-크루거: ‘오만한 바보’가 아니라 ‘자기채점의 실패’입니다
더닝-크루거 효과는 코넬 대학교의 데이비드 더닝(David Dunning)과 저스틴 크루거(Justin Kruger)가 1999년 발표한 논문에서 처음 소개된 개념입니다. 우리가 흔히 보는 요란한 곡선과 달리, 원논문이 보여준 핵심은 훨씬 담백합니다.
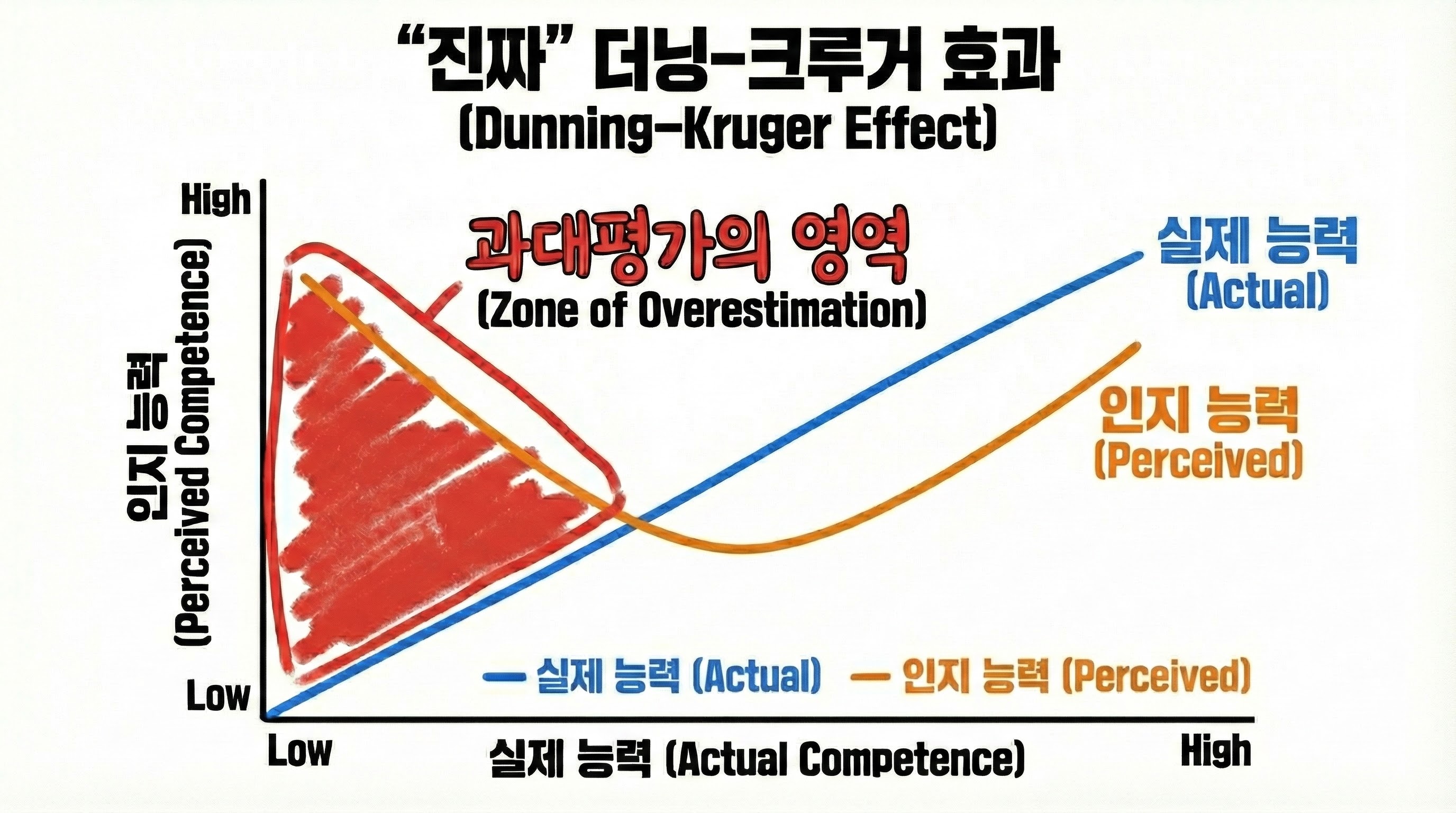
연구진은 참가자들에게 과제를 풀게 한 뒤, “당신은 상위 몇 퍼센트일 것 같습니까?”를 물었습니다. 그 결과, 하위 성취자일수록 자기평가가 크게 빗나가는 경향이 확인됩니다. 실제 성적이 12백분위인 사람들이 스스로를 62백분위쯤으로 추정하는 식입니다.
여기서 중요한 오해 교정이 하나 있습니다. 더닝-크루거는 “초보가 전문가보다 자신감이 더 높다”는 이야기가 아닙니다. 절대적인 자신감의 크기가 아니라, ‘내가 어느 위치인지’를 맞추는 정확도, 즉 자기평가의 보정이 무너진다는 이야기입니다.
왜 하위 성취자에서 오차가 커질까요? 이유는 단순합니다. 실력이 부족하면 대개 두 가지가 함께 부족해집니다.
문제를 푸는 능력,
내가 왜 틀렸는지 알아차리는 능력입니다.
못하는데, 못하는 걸 판별할 ‘기준’도 부족하니, 틀려도 틀린 줄 모르기 쉽습니다. 이것이 더닝-크루거가 말한 메타인지의 함정입니다.
4장. 생성형 AI 시대의 우리는: 봉우리는 더 높아지고, 계곡은 더 깊어졌습니다

이제 무대를 생성형 AI로 옮기면, 이 곡선은 더 쉽게 현실이 됩니다. LLM은 결과를 너무 빨리 보여줍니다. 보고서가 즉시 정리되고, 코드가 돌아가고, 설명이 그럴듯하게 완성됩니다. 그러면 사람은 자신이 ‘이해해서’ 한 것과 ‘도움받아서’ 된 것을 섞어 느끼기 쉽습니다. 경계가 흐려지는 순간, 자기평가는 더 어려워집니다.
게다가 AI의 답변은 대체로 매끄럽습니다. 문장이 유려하면 내용도 맞아 보이는 착각이 생깁니다. 그리고 사람은 생각을 맡기기 시작합니다. “AI가 했으니 맞겠지”라는 마음으로 검증을 생략하게 됩니다.
실제 연구에서도 비슷한 장면이 관찰됩니다. AI를 사용하면 과제 성과는 좋아질 수 있지만, 사람들은 자신이 얼마나 잘했는지 판단을 더 정확히 하지는 못하고, 오히려 성과를 과대평가하는 경향이 나타났습니다.
결론. 그래서 답은 ‘딥다이브’입니다

결국 결론은 단순합니다. AI 시대의 메타인지는, ‘너 자신을 알라’에서 ‘너의 무지를 추적하라’로 진화합니다. 그리고 그 추적은 거창한 결심이 아니라, 세 가지 습관으로 시작됩니다.
첫째, 검증입니다. 출처·근거·반례를 한 번만 더 보는 겁니다.
둘째, 프레이밍입니다. 답을 구하기 전에 “내가 진짜로 결정하려는 게 무엇인가”를 먼저 적어 보는 겁니다.
셋째, 딥다이브입니다. 요약을 멈추고 핵심 개념 하나만큼은 ‘내 말로’ 끝까지 설명해 보는 겁니다. 설명이 막히는 지점이 바로 지금 추적해야 할 무지입니다.
그래프 하나로 사람을 규정하기 쉬운 시대입니다. 하지만 그 그래프가 틀렸다는 사실을 아는 순간, 우리는 더 중요한 걸 배웁니다. 남의 봉우리를 찾는 능력이 아니라, 내 안의 ‘확신이 먼저 뛰어오르는 지점’을 먼저 알아차리는 능력. 그게 AI 시대에 가장 값비싼 실력입니다.
출처