바이브코딩으로 CES 2026 페이지를 이틀 만에 만들었습니다
“CES 2026 혁신상, 한국 기업이 절반 이상을 휩쓸었다.”
이런 이야기를 여기저기서 접했습니다.
그런데 막상 확인해보려니, 이상하게도 한눈에 볼 수 있는 사이트나 리스트가 없었습니다.
어떤 기업이, 어떤 제품으로, 어떤 분야에서 수상했는지
정리된 형태로 확인할 수 있는 곳이 없더군요.
그래서 그냥,
직접 만들기로 했습니다.
결론부터 말하면 이틀 만에 초안을 만들었고,
그 이후 4일 동안 안정화와 검증 작업을 진행했습니다.
👉 CES 2026 정리 페이지
https://uslab.ai/ko/ces
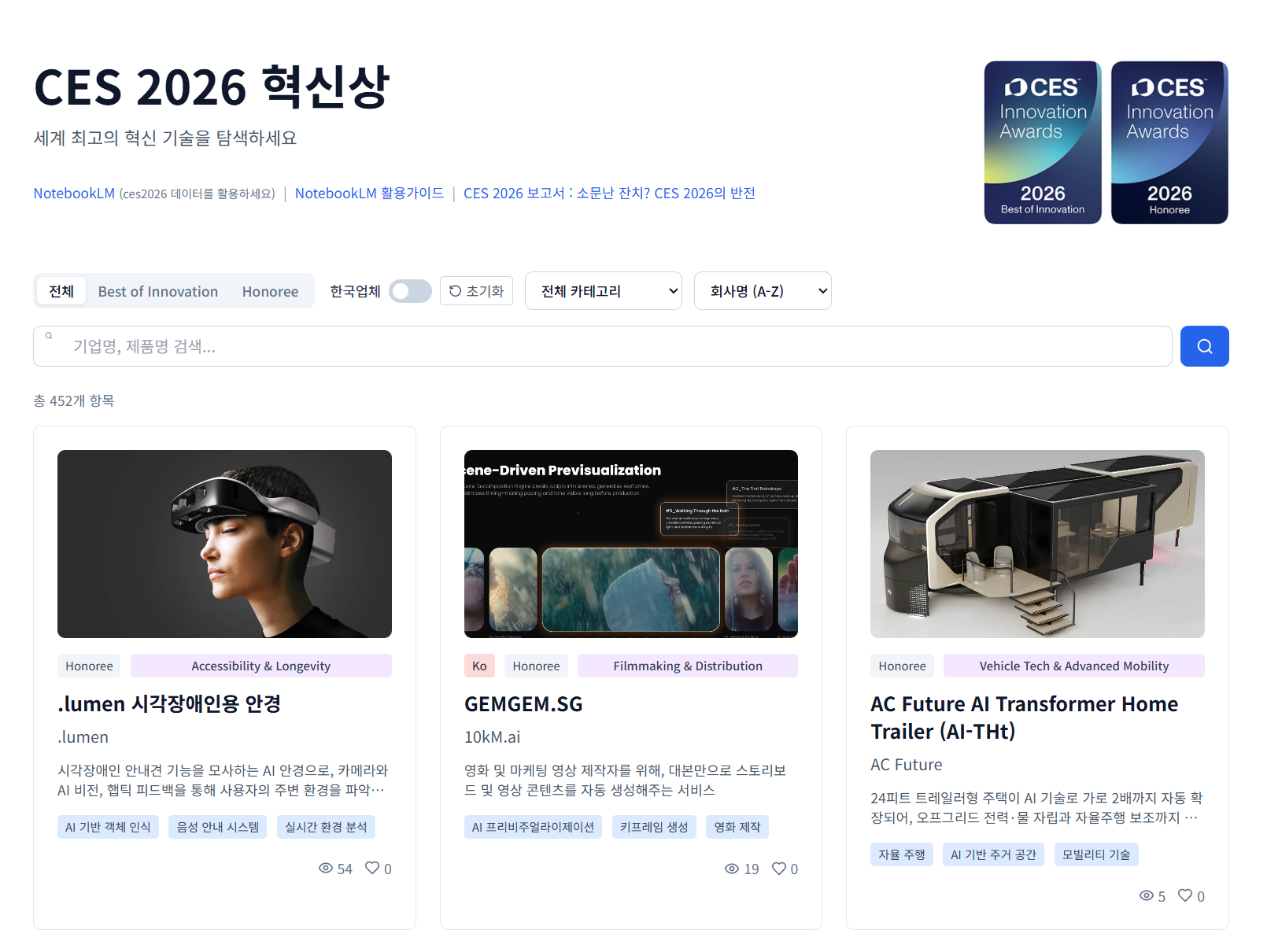
목록에서 제품을 클릭하면,
각 항목마다 딥리서치를 통해 정리한 분석 내용을 확인할 수 있습니다.
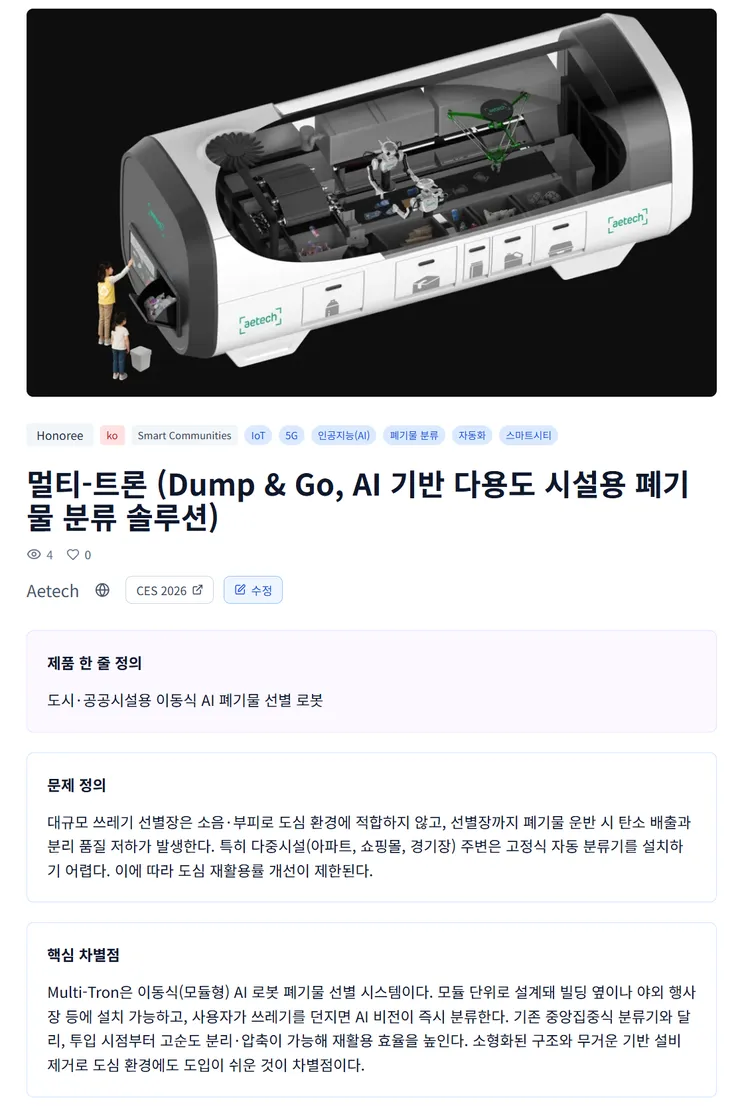
1. 이번에는 ‘자료 인용’이 아니라, ‘제대로 분석’을 하고 싶었습니다
CES 공식 페이지를 보면 각 수상작은 보통 아래 정도의 정보만 제공됩니다.
한 장짜리 설명
간단한 제품 소개
https://www.ces.tech/ces-innovation-awards/
하지만 개인적으로는 그게 늘 아쉬웠습니다.
이 회사가 한국 기업인지
회사 공식 홈페이지는 어디인지
이 제품이 왜 나왔고
누가 먼저 도입할 가능성이 있는지
이런 정보가 있어야 “봤다”가 아니라 “판단했다”고 말할 수 있다고 생각했기 때문입니다.
그래서 단순히 일부를 발췌하는 방식이 아니라,
전체를 수집한 뒤 딥리서치로 다시 해석하기로 했습니다.
2. 설계는 GPT·Gemini, 구현은 Cursor (바이브코딩)
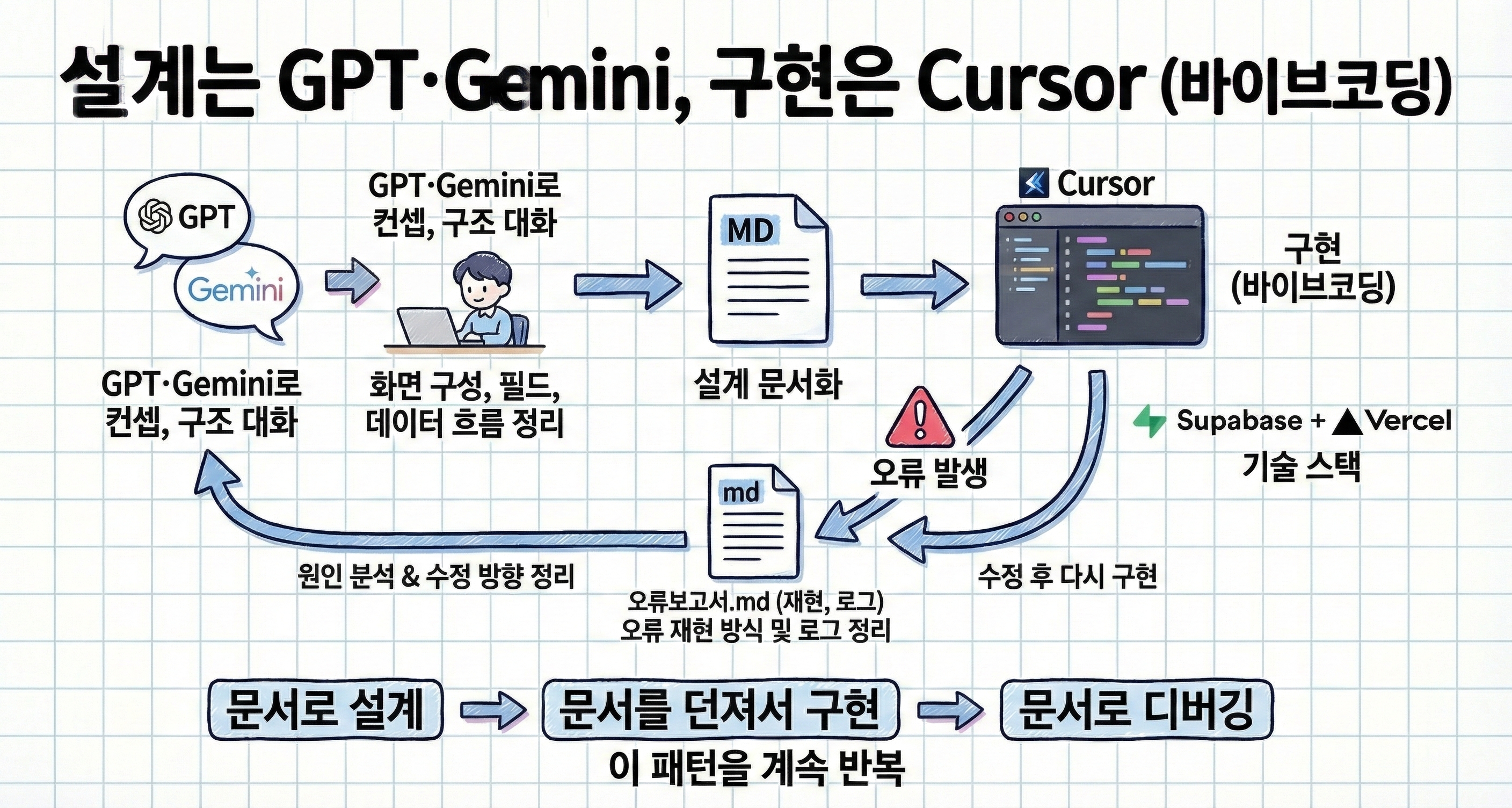
이번 프로젝트의 작업 방식은 꽤 단순했습니다.
GPT와 Gemini로 전체 컨셉과 구조에 대해 충분히 대화를 나눕니다
화면 구성, 필드, 데이터 흐름을 정리합니다
설계가 확정되면 그 내용을 MD 파일로 문서화합니다
그 문서를 그대로 Cursor에 전달해 구현합니다
구현 과정에서 오류가 생기면
오류 재현 방식과 로그를 정리한
**오류보고서.md**를 다시 만듭니다GPT와 Gemini와 함께 원인을 쪼개고
수정 방향을 정리해 다시 Cursor로 돌아갑니다
정리하면,
문서로 설계 → 문서를 던져서 구현 → 문서로 디버깅
이 패턴을 계속 반복했습니다.
기술 스택은 Supabase + Vercel 조합으로 구성했습니다.
3. 일단 452개를 ‘전부’ 모았습니다
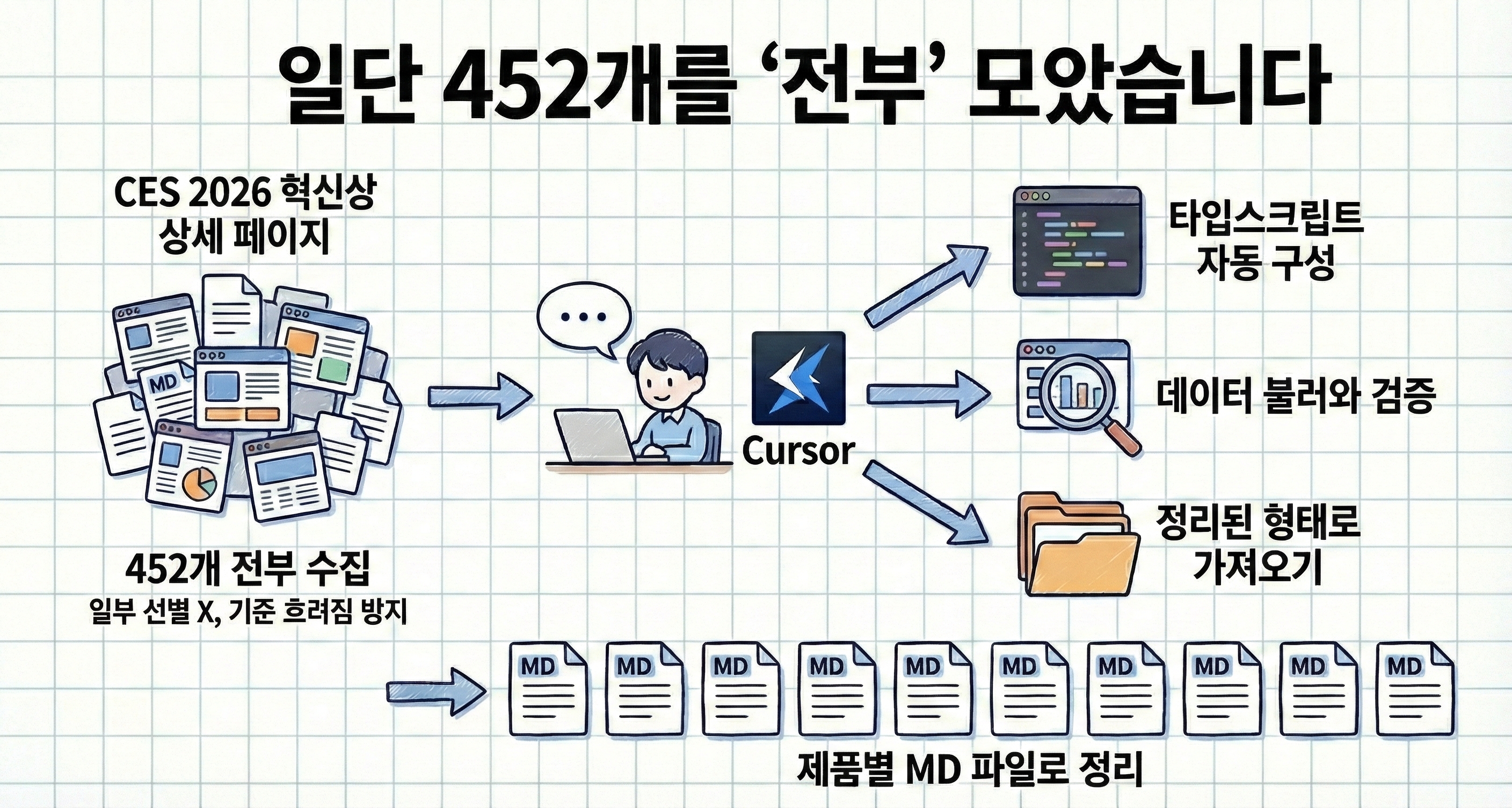
처음부터 일부만 선별하는 방식은 쓰지 않았습니다. 그 순간부터 기준이 흐려질 것 같았기 때문입니다. 그래서 CES 2026 혁신상 상세 페이지 기준으로총 452개 제품을 전부 수집했습니다.
Cursor에게 사이트 구조를 알려주고 크롤링을 요청했더니,
타입스크립트를 자동으로 구성하고
데이터를 불러와 검증하고
정리된 형태로 가져오더군요.
수집된 데이터는 제품별로 하나씩 MD 파일로 정리했습니다.
4. 딥리서치: 452개를 한 번에 돌릴 수는 없었습니다
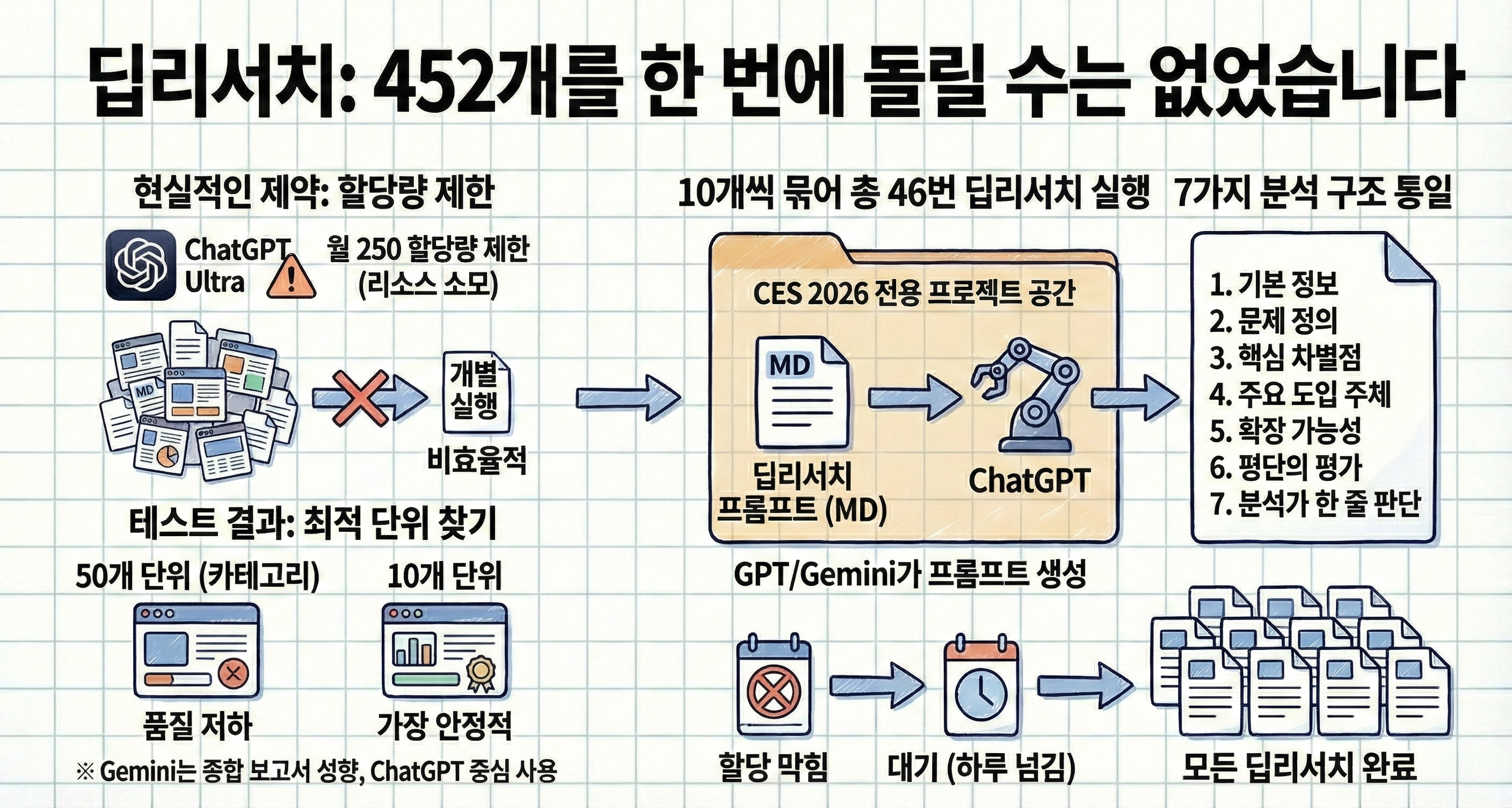
여기서 현실적인 제약이 있었습니다.
ChatGPT Ultra 요금제를 사용하고 있었는데, 딥리서치 할당량이 월 250으로 제한되어 있었습니다. (횟수라기보다는 내부 리소스 소모 구조에 가까웠습니다) 452개를 개별로 돌리는 건 비효율적이었고, 처음에는 카테고리 단위로 묶어봤지만 한 카테고리에 50개씩 들어가면 분석 품질이 눈에 띄게 떨어졌습니다.
테스트 결과,
10개 단위가 가장 안정적이었습니다.
그래서:
452개를
10개씩 묶어
총 46번의 딥리서치를 진행했습니다.

딥리서치 프롬프트는 MD 파일로 따로 정리했고, 분석 구조는 아래 7가지로 통일했습니다.
기본 정보 (기업명 / 홈페이지 / 한국 기업 여부 / 제품 한 줄 정의)
문제 정의
핵심 차별점
주요 도입 주체
확장 가능성
평단의 평가
분석가 한 줄 판단
프롬프트 자체는 GPT와 Gemini가 거의 다 만들어줬습니다. 대화창이 복잡해지는 걸 피하기 위해
CES 2026 전용 프로젝트 공간을 따로 만들어 그 안에서 딥리서치를 돌렸습니다.
ChatGPT는 10개 단위로 원하는 방향의 딥리서치를 안정적으로 수행했고, Gemini는 종합 보고서 성향이 강해 이번 프로젝트에서는 ChatGPT 중심으로 사용했습니다.
중간에 할당이 막히기도 했고, 하루를 넘겨가며 조금씩 풀리는 걸 기다리기도 했지만, 결과적으로 모든 딥리서치를 완료했습니다.
5. 프로토타입은 이틀, 진짜 작업은 그 이후였습니다
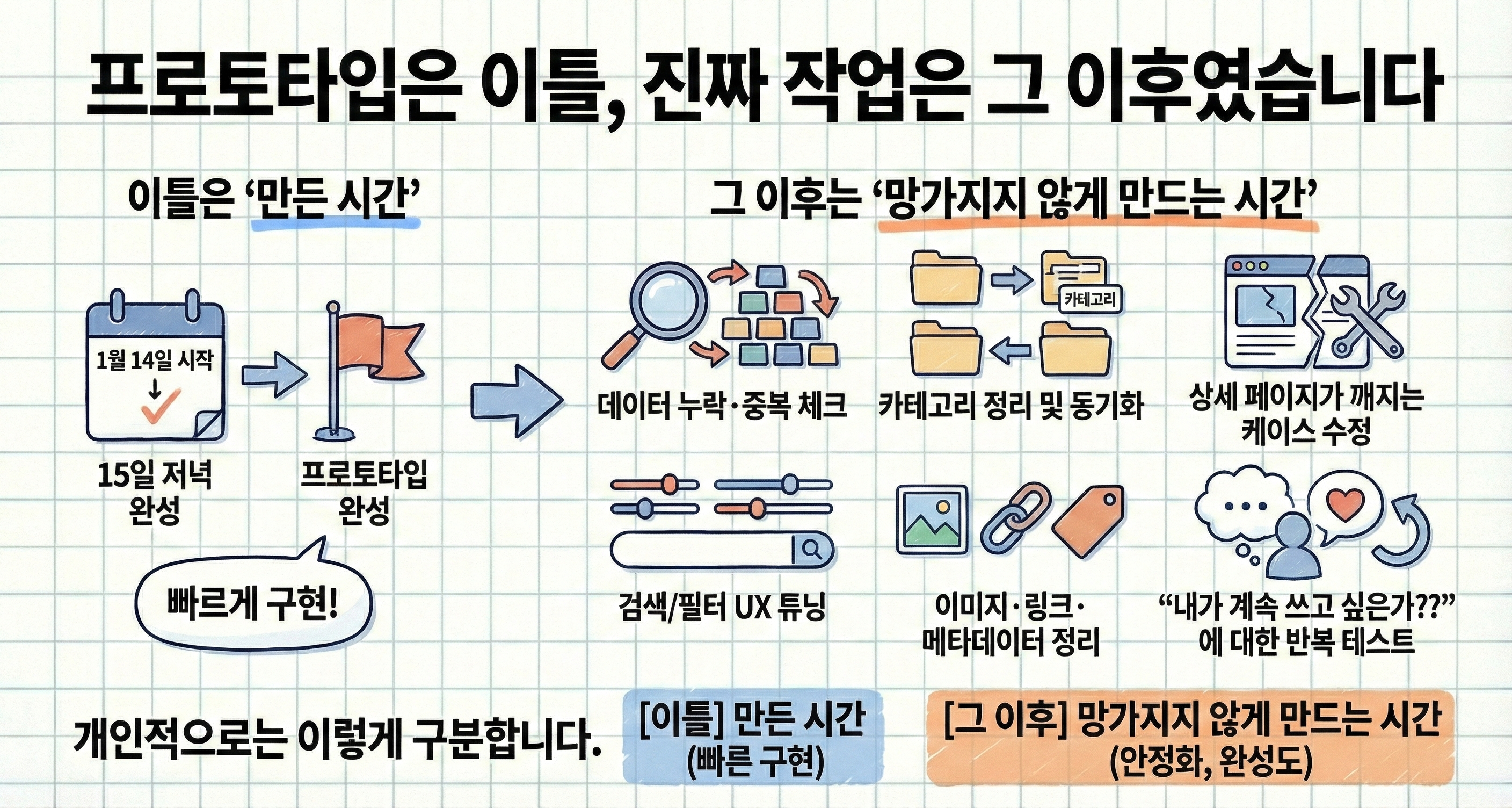
프로젝트는 1월 14일에 시작했고, 15일 저녁에 프로토타입이 완성됐습니다.
하지만 체감상 진짜 작업은 그 이후였습니다.
데이터 누락·중복 체크
카테고리 정리 및 동기화
상세 페이지가 깨지는 케이스 수정
검색/필터 UX 튜닝
이미지·링크·메타데이터 정리
무엇보다 “내가 계속 쓰고 싶은가?”에 대한 반복 테스트
그래서 개인적으로는 이렇게 구분하고 있습니다.
이틀은 ‘만든 시간’ 그 이후는 ‘망가지지 않게 만드는 시간’
숫자에 대해 한 가지 짚고 넘어가면
기사에서는 혁신상을 받은 기업이 357곳이라고 나오기도 하지만, 실제로 CES 공식 사이트의 상세 페이지를 기준으로 수집해보니 총 452개 항목이었습니다.
이전 수상 이력 + CES 2026 행사 과정에서 추가로 노출되는 구조 때문으로 보였고, 생각보다 정리해야 할 데이터가 더 많다는 점에서 저 스스로도 조금 놀랐습니다.
정리하며
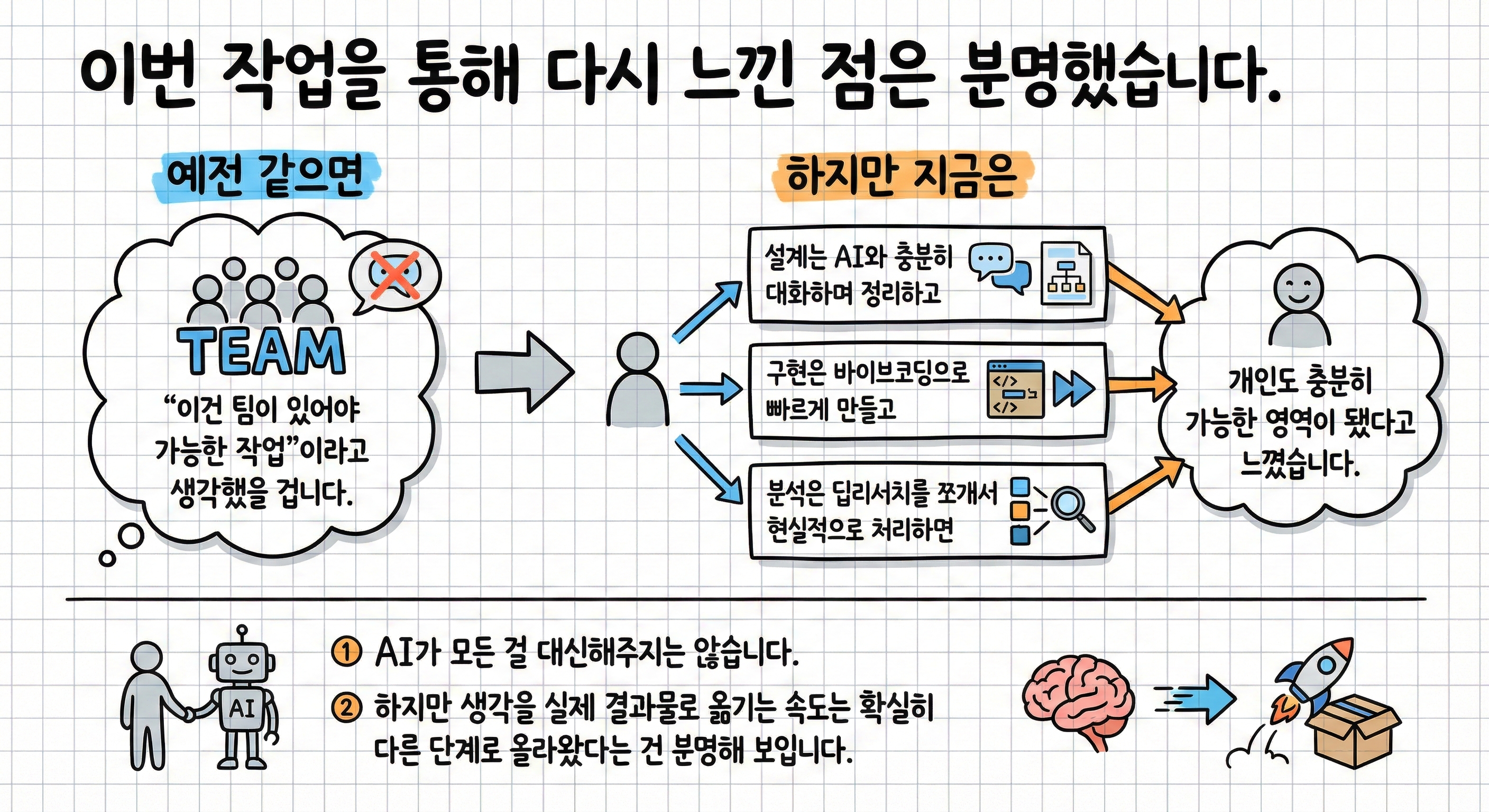
이번 작업을 통해 다시 느낀 점은 분명했습니다.
예전 같으면
“이건 팀이 있어야 가능한 작업”이라고 생각했을 겁니다.
하지만 지금은
설계는 AI와 충분히 대화하며 정리하고
구현은 바이브코딩으로 빠르게 만들고
분석은 딥리서치를 쪼개서 현실적으로 처리하면
개인도 충분히 가능한 영역이 됐다고 느꼈습니다.
이렇게 정리된 데이터는 MD 파일로 저장해 NotebookLM에 넣어 활용하고 있습니다.
개인 리포트를 만들거나,
관심 있는 주제만 다시 파고들기에도 적당합니다.
👉 CES 2026 정리 : https://uslab.ai/ko/ces
👉 NotebookLM
https://notebooklm.google.com/notebook/b7e0cea7-a0e2-4aa7-a4f1-58b43de862ca
👉 NotebookLM 활용가이드
https://uslab.ai/ko/blog/ces-2026-notebooklm-complete-guide
AI가 모든 걸 대신해주지는 않습니다.
하지만 생각을 실제 결과물로 옮기는 속도는 확실히 다른 단계로 올라왔다는 건 분명해 보입니다.